ML Inference on Backend vs Frontend
A comparison of ML inference speed and memory consumption across various batch sizes on both GPU and CPU.
June 17, 2024
05m Read
By: Abhilaksh Singh Reen
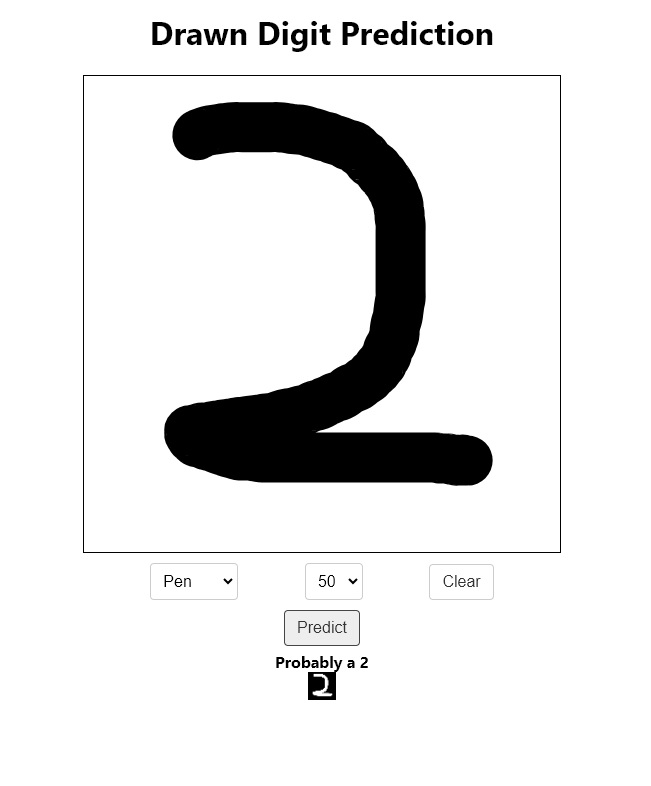
When I built my first ML app back in early 2022 using a CNN in TensorFlow, I wondered what was the best way to get my friends to use this. Back then I had no money and could not afford a server in the cloud, so I decided to run my model in TensorFlow.js and package the app into some static files that could be served on GitHub. These days, I work with huge models as part of ML Ops, so we mostly keep our things on the server side. But is that always the right way? In this Article, we answer that exact question.
To elaborate the comparison better, I'll be considering some requirements and discussing how I would go about implementing them. If you would like to skip directly to the advantages and disadvantages of each approach, click right here.
Some Examples
Let's think of a few ML Ops use cases.
Work Offline
Last week I was interviewing someone and they described how their team built an app that was used by farmers in the alpine regions of Eastern India. The app took images from the phone's camera, passed them to some transformer model, and displayed the output on screen. Due to the poor internet connectivity in these regions, the application had to be designed to work offline and the team knew from the start (a requirement in the SRS) that they could not host their model on a server and make API calls to it from the app. As a result, they had no option but to run inference on the Frontend which I believe they built using React Native (React or React Native ... it's still the Frontend).
In such a case, there is no option but to have the model run locally.
User Data Privacy
Most of the time, you will have the choice to have your model on the server. But, the lack of internet connectivity is not the only issue. Say you have an app that allows users to enter their bank statements and tells them the best investments they could make, or maybe you've built an AI Photo Enhancer or something similar that can make a user's images look better. In both of these cases, the data that the model takes as input is what the user would prefer to keep private. Your servers could have no data collection, and the application's source code could be open source.
But, as the layman user, I'm still sending my data to some servers, who knows whether or not they keep some of it?
The better option (the one that leaves no doubt in the user's mind) is to not have anything sent to your servers and keep the user's data on their device only. This necessitates that the inference is run locally.
Speed
AI Photo Enhancers use single images as inputs and the result can be delivered after a couple of seconds. But what about something that needs to process video and do it in real-time (like that Instagram Hair Color Filter). Sending a request to the backend and getting a response 30 to 60 times every second is out of the question. The algorithm needs to run locally.
Not only does the model have to be small (lower download size), it also has to be fast (run in real-time on the phone's GPU).
Sure, you could get much faster inference on a Nvidia A100 Server that crunches floating point operations like there's no tomorrow, but you would still have to send 30 images to the server every second. The latency induced by the requests is much greater than the gain from putting the model on the server.
Privacy the other way - keeping the Model a Secret
We've talked about User Privacy but what about the company's privacy? If you have a state-of-the-art model that nobody in the world can replicate, or if you have a paid subscription for users to use your model, you probably don't wanna put it on the client side from where anyone can access the model's architecture or weights. Code can be obfuscated and applications can be compiled into binaries, but neither of these is gonna stop a determined pirate with the right tools from getting to your model. If you wanna keep it safe, not having it on the client side is the way to go.
Speed 2.0
While small models running locally can provide inference in real-time, this is not true for bigger models. As the model's size increases you need faster and faster hardware to run it in a decent amount of time. The hardware available on the client side may not be enough. So it makes much more sense to have the model on a server somewhere running on the best GPU. A single server could serve multiple devices and each user will get the response in a few milliseconds.
And it gets better. If the server receives many requests every second, it can put two or more requests from different users into the same batch and then pass that batch to the model. GPUs are efficient at parallel processing and batched inference allows us to make the most out of it. In this Post, I show how the inference time decreases with large batch sizes and their effect on GPU memory consumption, check it out for more info.
Finally, the user cannot be expected to download a 4 GB model to run the application. So, for very large models, it makes much more sense to have them on the server side.
Suitability of Each Approach
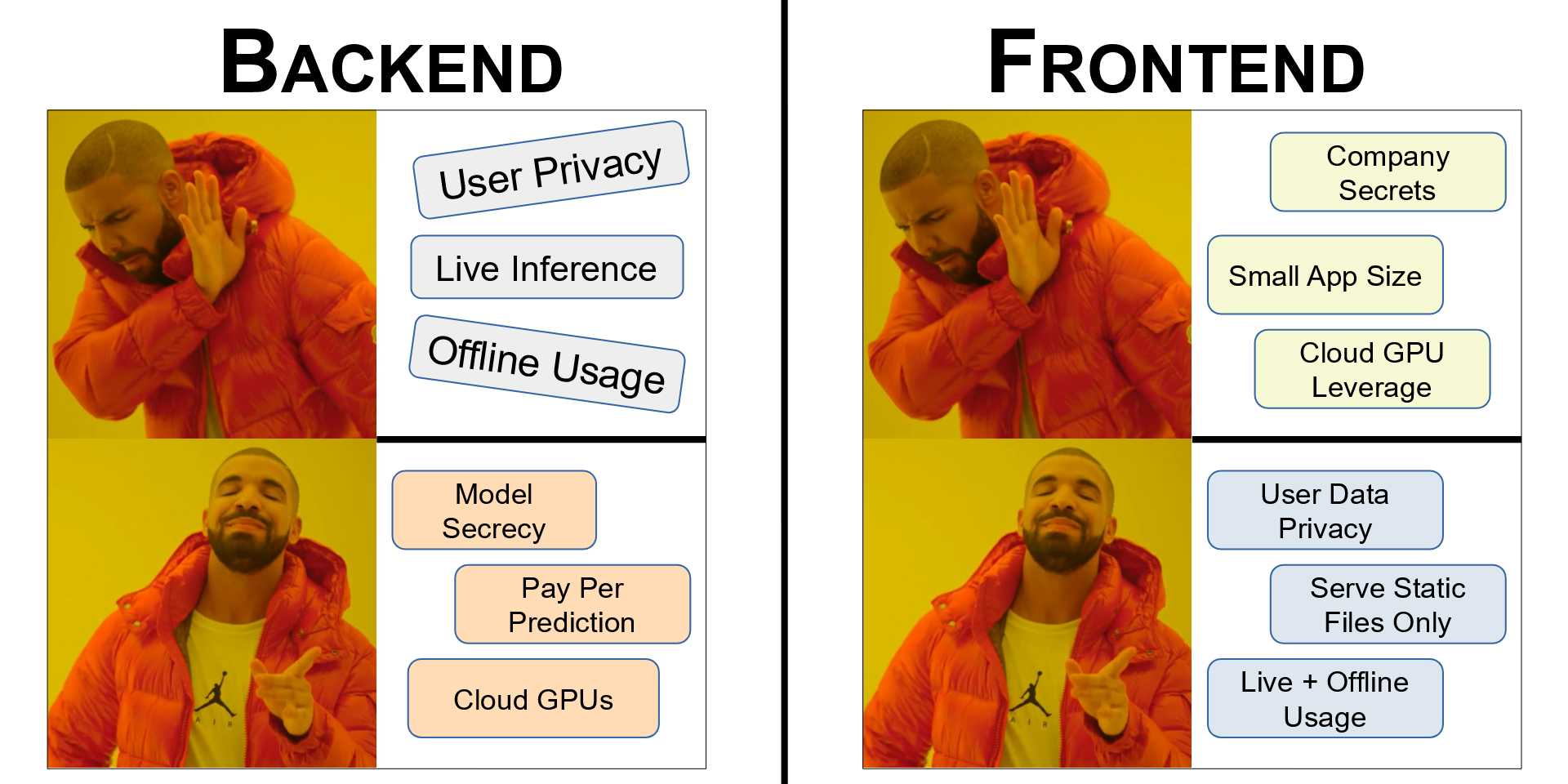
We've seen how either approach allows us some capabilities that the other does not. Below, we've summarized the advantages of both methods.
Backend Side
1) Model architecture and weights remain private (especially useful if you have a state-of-the-art product or are running a paid service)
1) Large models (could be a few gigabytes) are difficult to download on the Frontend so server-side inference is the more convenient option.
1) Inference speeds will be identical across devices since the model runs in the Cloud on perhaps the best GPU.
1) If the process involves making multiple database calls, contacting other APIs or microservices, and running multiple inference sessions - it's probably best to keep this on the server side.
Frontend Side
1) User Data remains protected - it's not sent to a server.
1) Hosting of the system becomes a lot easier since we only have to serve static files for the Frontend.
1) No latency in communicating with the backend - leads to faster inference for smaller models and allows for live processing.
1) Inference will work offline.
Conclusion
So, which is it then: Backend or Frontend? Well, like most problems in Software Engineering, there is no right answer, there are only trade-offs. AS we've seen, ML models on the server side or the client side both have their own benefits and it's up to you to choose the way that suits your application the best.
Once you've chosen the right way to deploy your model, you will be looking for how to do it. In the Blog Posts listed below, I deploy the same model (a simple CNN) in 6 different ways. Pick the method of your choice and Read On!
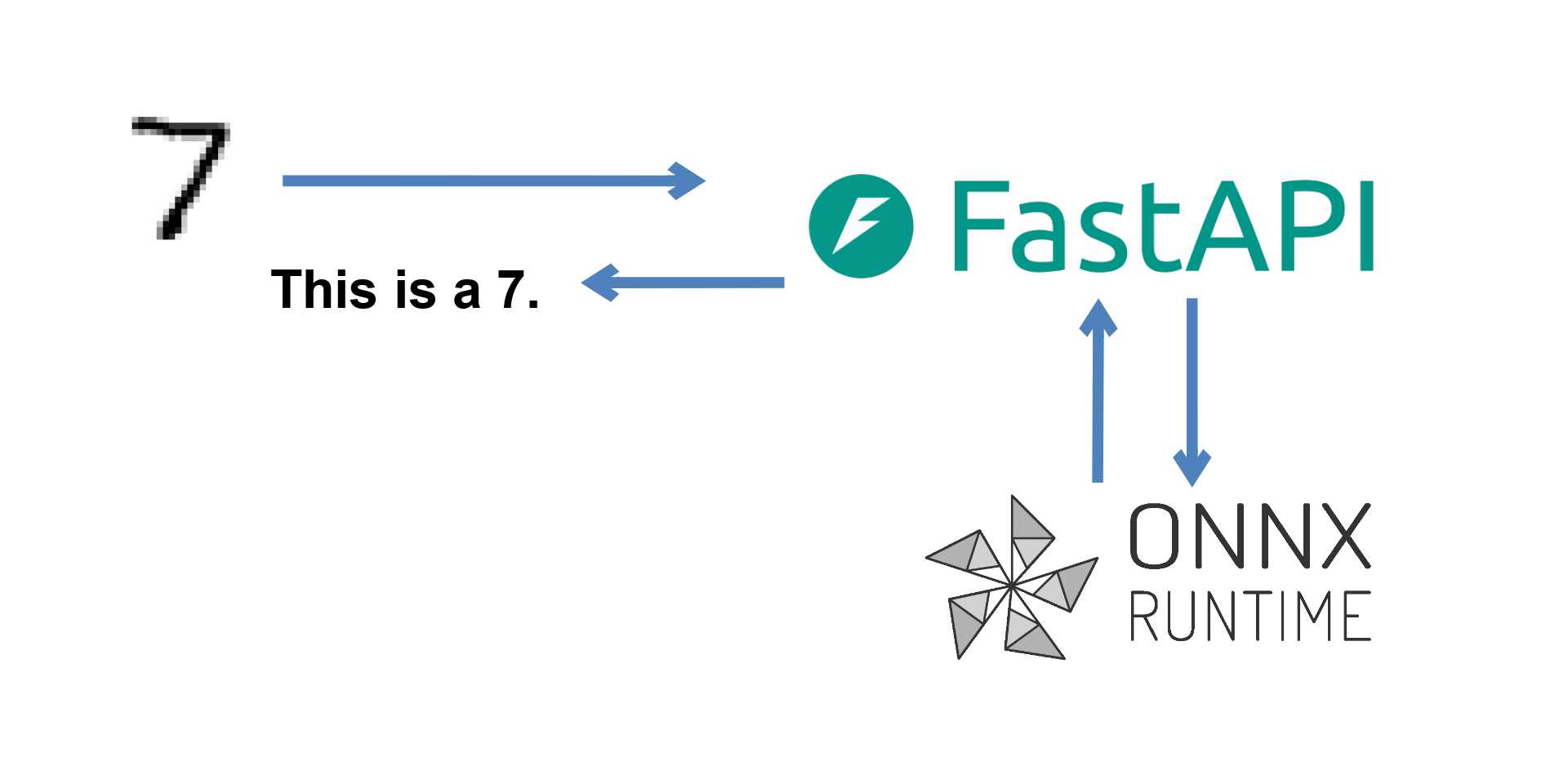
1) On Backend:
b) Python: Flask and TensorFlow
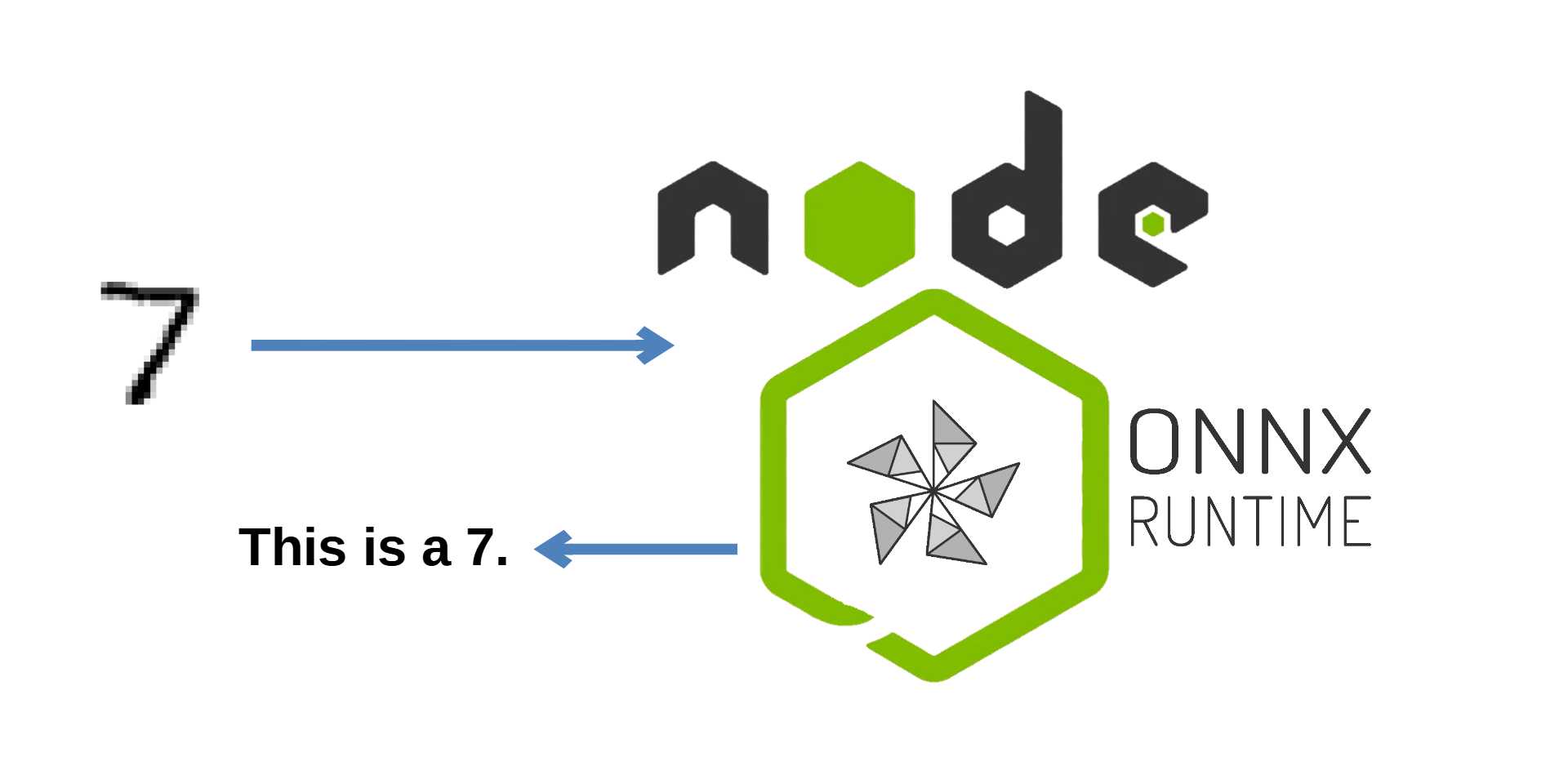
2) On Frontend:
See you next time :)