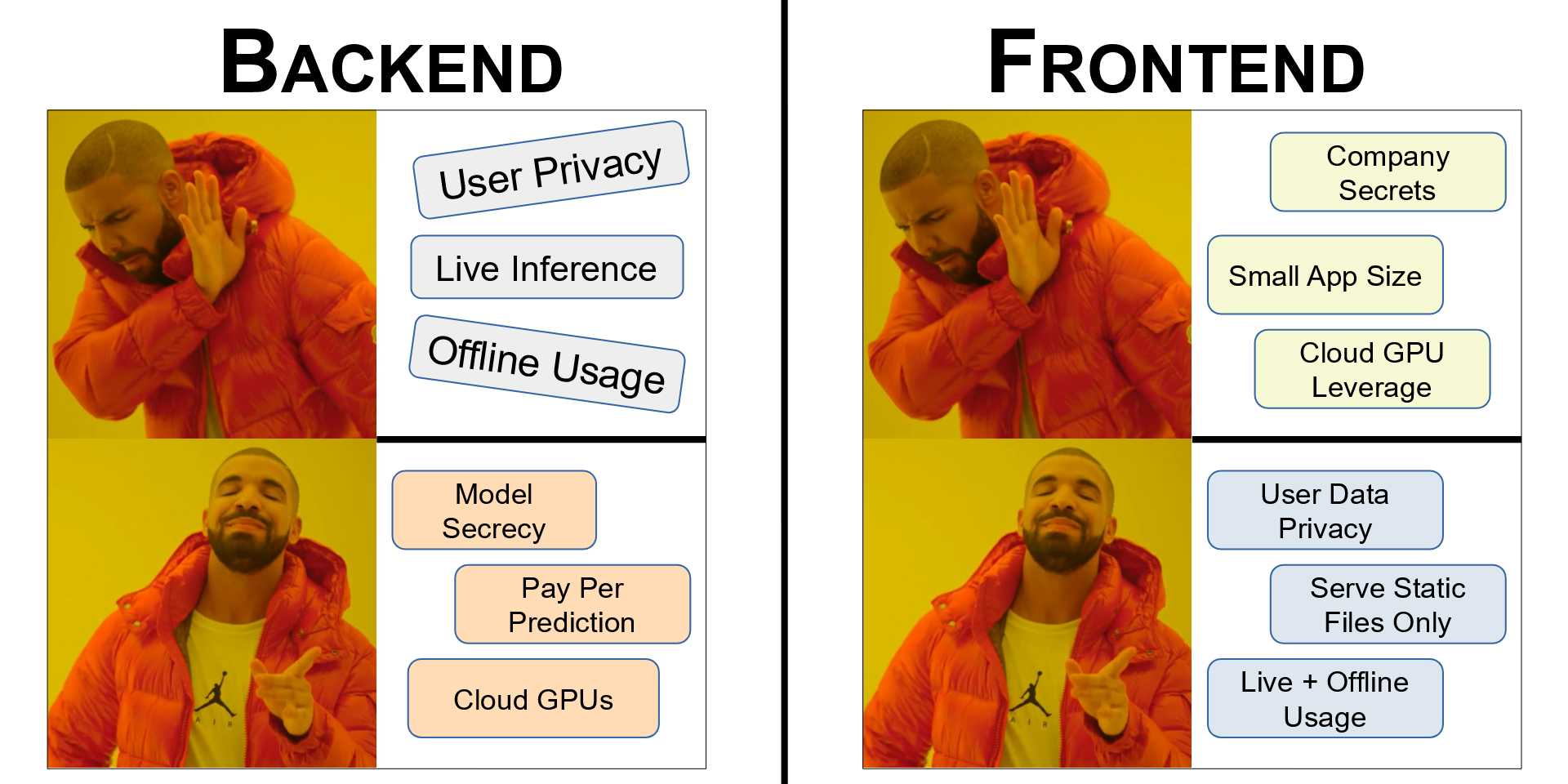
Express.js API for Inference using an ONNX Model
Deploying an ONNX Model using Express.js.
July 17, 2024
08m Read
By: Abhilaksh Singh Reen
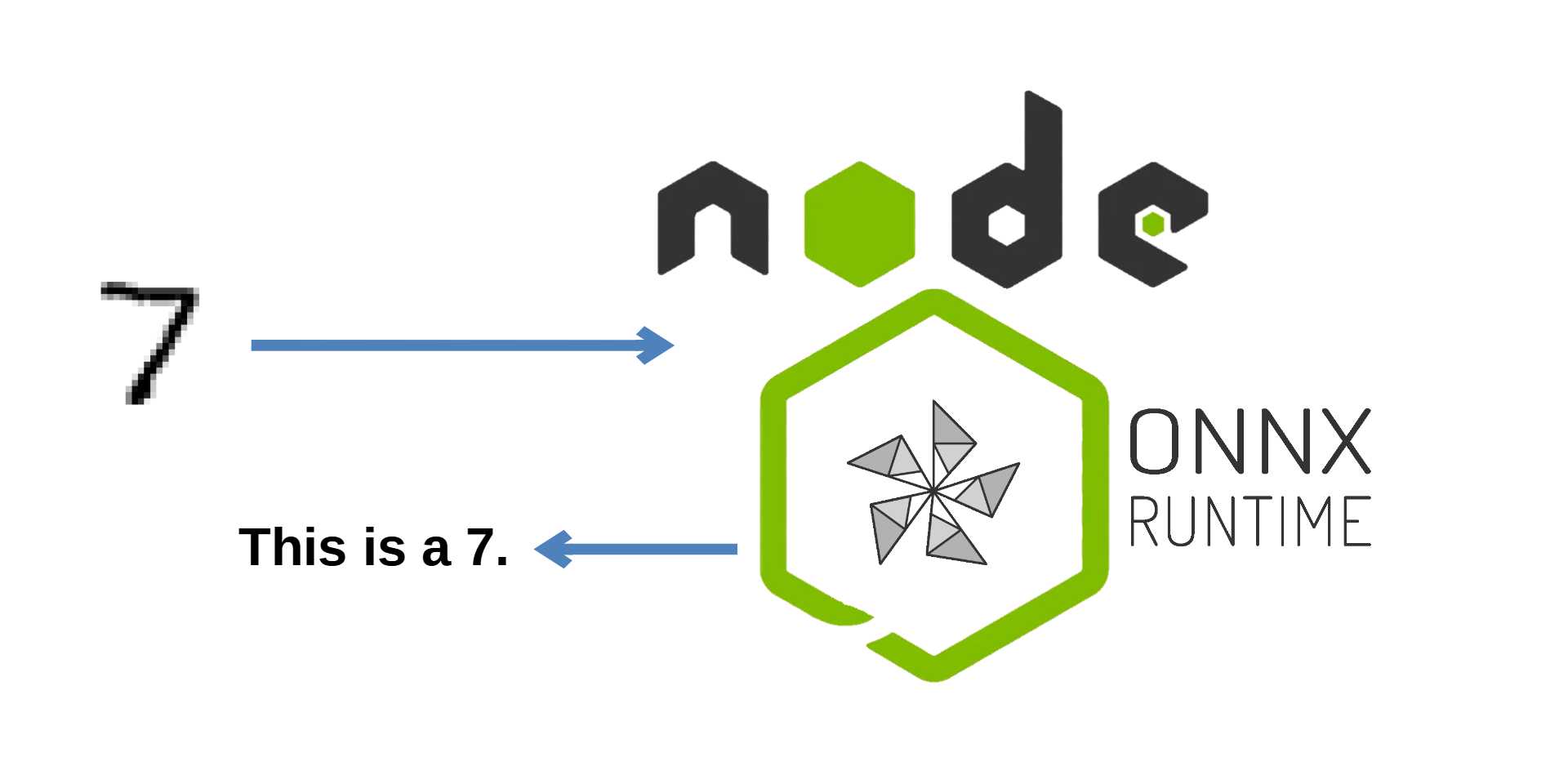
In today's Article, we'll deploy the ONNX model we created (and exported) in a previous Post on an Express.js server.
The GitHub repository for this codebase can be found here.
Server Setup
Let's create a new node project and install some dependencies.
npm init -y
npm install express multer onnxruntime-node sharpexpress is our web server, multer is for handling multipart/form-data, onnxruntime-node allows us to run inference operations on ONNX models, and sharp is an image processing library for Node.
Inside the project's root directory, create a new folder called src. The final folder structure will look something like the following:
│ package-lock.json
│ package.json
│
├───models
└───src
config.js
imageProcessing.js
mathUtils.js
server.jsOf course, we haven't created any of those files in the src folder yet.
Config
Create the file src/config.js:
const path = require('path');
const modelsDir = path.join(__dirname, '..', 'models');
module.exports = {modelsDir}Here, we've just defined a variable to store the path to our models directory.
ORT Session and Server Initialization
Next, in the src folder, create a file called server.js.
const fs = require("fs").promises;
const path = require("path");
const express = require("express");
const multer = require("multer");
const ort = require("onnxruntime-node");
const { modelsDir } = require("./config");
const PORT = process.env.PORT || 8000;
// const modelPath = path.join(modelsDir, "trainingId", "model.onnx")
const modelPath = path.join(modelsDir, "torch---2024-04-23-08-25-15", "model.onnx");
const app = express();
const multipartMiddleware = multer({ dest: "cache/" });
async function startServer() {
const ortSession = await ort.InferenceSession.create(modelPath);
app.post("/api/run-inference", multipartMiddleware.single("file"), async (req, res) => {
res.status(200);
res.send({
predicted_label: 0,
});
});
app.listen(PORT, () => {
console.log(`Server is running on http://localhost:${PORT}`);
});
}
startServer();We have to create an async function to create the InferenceSession because that is an async operation that needs to be awaited and Node does not support top-level await. After that, we define our inference endpoint and set the server to listen at the specified port.
Before we can move on with writing our inference logic, we'll need some helper functions to preprocess our image and postprocess the model's output.
Math Utils
Let's work on the src/mathUtils.js file next.
function softmax(resultArray) {
const largestNumber = Math.max(...resultArray);
const sumOfExp = resultArray
.map((resultItem) => Math.exp(resultItem - largestNumber))
.reduce((prevNumber, currentNumber) => prevNumber + currentNumber);
return resultArray.map((resultValue, index) => {
return Math.exp(resultValue - largestNumber) / sumOfExp;
});
}
function indexMax(arr) {
if (arr.length === 0) {
return -1;
}
let max = arr[0];
let maxIndex = 0;
for (let i = 1; i < arr.length; i++) {
if (arr[i] > max) {
maxIndex = i;
max = arr[i];
}
}
return maxIndex;
}
module.exports = { softmax, indexMax };We have a function called softmax that serves as a replacement for torch.nn.Softmax and another function that's a DIY equivalent of numpy.argmax.
Image Processing
In the src directory, create a file called imageProcessing.js.
const ort = require("onnxruntime-node");
const sharp = require("sharp");
const inputImageShape = [28, 28];
const inputShape = [1, 1, 28, 28];
async function loadImageAsUint8Array(imagePath) {
const image = sharp(imagePath).resize(inputImageShape[0], inputImageShape[1]).greyscale();
const rawImage = image.raw();
const imageBuffer = await rawImage.toBuffer();
const imageUint8Array = new Uint8Array(imageBuffer);
return imageUint8Array;
}
function imageArrayToTensor(imageUint8Array) {
let tensorValues = new Float32Array(imageUint8Array.length);
for (let i = 0; i < imageUint8Array.length; i++) {
tensorValues[i] = imageUint8Array[i] / 255;
}
const imageTensor = new ort.Tensor("float32", tensorValues, inputShape);
return imageTensor;
}
module.exports = { loadImageAsUint8Array, imageArrayToTensor };Here we have two helper functions. One loads an image from a path, resizes it to 28x28, makes it greyscale, and puts it into a Uint8 Array. The other function converts that array to a Tensor of inputShape.
Input Shape
But, how did we get the input shape? Well, since we trained the model ourselves, we kinda know what shape it's expecting the input to be in. But, what if we had to find out? To do so, we can use a tool like Netron to visualize our ONNX model. If we open up the model in Netron, we see that the input it wants in of the shape (1x1x28x28) and that's the shape we want our image tensor to be.

Inference
Let's head back to src/server.js. First, we'll import the four functions we just created from their respective files.
const { loadImageAsUint8Array, imageArrayToTensor } = require("./imageProcessing");
const { softmax, indexMax } = require("./mathUtils");Now, in our route handler, we can write the inferencing logic.
app.post("/api/run-inference", multipartMiddleware.single("file"), async (req, res) => {
if (!req.file) {
return res.status(400).send("No file uploaded.");
}
const imagePath = req.file.path;
const imageArr = await loadImageAsUint8Array(imagePath);
const imageTensor = imageArrayToTensor(imageArr);
const feeds = {
[ortSession.inputNames[0]]: imageTensor,
};
const outputData = await ortSession.run(feeds);
const output = outputData[ortSession.outputNames[0]];
const outputSoftmax = softmax(Array.prototype.slice.call(output.data));
const outputClass = indexMax(outputSoftmax);
await fs.unlink(imagePath);
res.status(200);
res.send({
predicted_label: outputClass,
});
});We load the image as a Uint8 Array and then convert it to a tensor. Then, we construct the feeds we'll pass to our session, the output of which first goes through our DIY softmax and then our DIY argmax. Since the output classes are only from 0-9, the output of the argmax is the prediction label. We delete the image from the cache folder and then return the prediction in a JSON response.
Here's the entire server.js file.
const fs = require("fs").promises;
const path = require("path");
const express = require("express");
const multer = require("multer");
const ort = require("onnxruntime-node");
const { modelsDir } = require("./config");
const { loadImageAsUint8Array, imageArrayToTensor } = require("./imageProcessing");
const { softmax, indexMax } = require("./mathUtils");
const PORT = process.env.PORT || 8000;
// const modelPath = path.join(modelsDir, "trainingId", "model.onnx")
const modelPath = path.join(modelsDir, "torch---2024-04-23-08-25-15", "model.onnx");
const app = express();
const multipartMiddleware = multer({ dest: "cache/" });
async function startServer() {
const ortSession = await ort.InferenceSession.create(modelPath);
app.post("/api/run-inference", multipartMiddleware.single("file"), async (req, res) => {
if (!req.file) {
return res.status(400).send("No file uploaded.");
}
const imagePath = req.file.path;
const imageArr = await loadImageAsUint8Array(imagePath);
const imageTensor = imageArrayToTensor(imageArr);
const feeds = {
[ortSession.inputNames[0]]: imageTensor,
};
const outputData = await ortSession.run(feeds);
const output = outputData[ortSession.outputNames[0]];
const outputSoftmax = softmax(Array.prototype.slice.call(output.data));
const outputClass = indexMax(outputSoftmax);
await fs.unlink(imagePath);
res.status(200);
res.send({
predicted_label: outputClass,
});
});
app.listen(PORT, () => {
console.log(`Server is running on http://localhost:${PORT}`);
});
}
startServer();Conclusion
Previously, we had learned how to convert models to ONNX, and today, we found out how to run one of those converted models in Node.js using the ONNX Runtime. For inference purposes, ONNX is a fast and robust solution. If we wanna make use of machine learning in our Node.js application, we don't have to create a separate API in Python and call that from our app, we can now run the inference in Node itself.
See you next time :)