Serving a TensorFlow Model using FastAPI
Learn how to serve a TensorFlow model with FastAPI.
August 26, 2024
05m Read
By: Abhilaksh Singh Reen
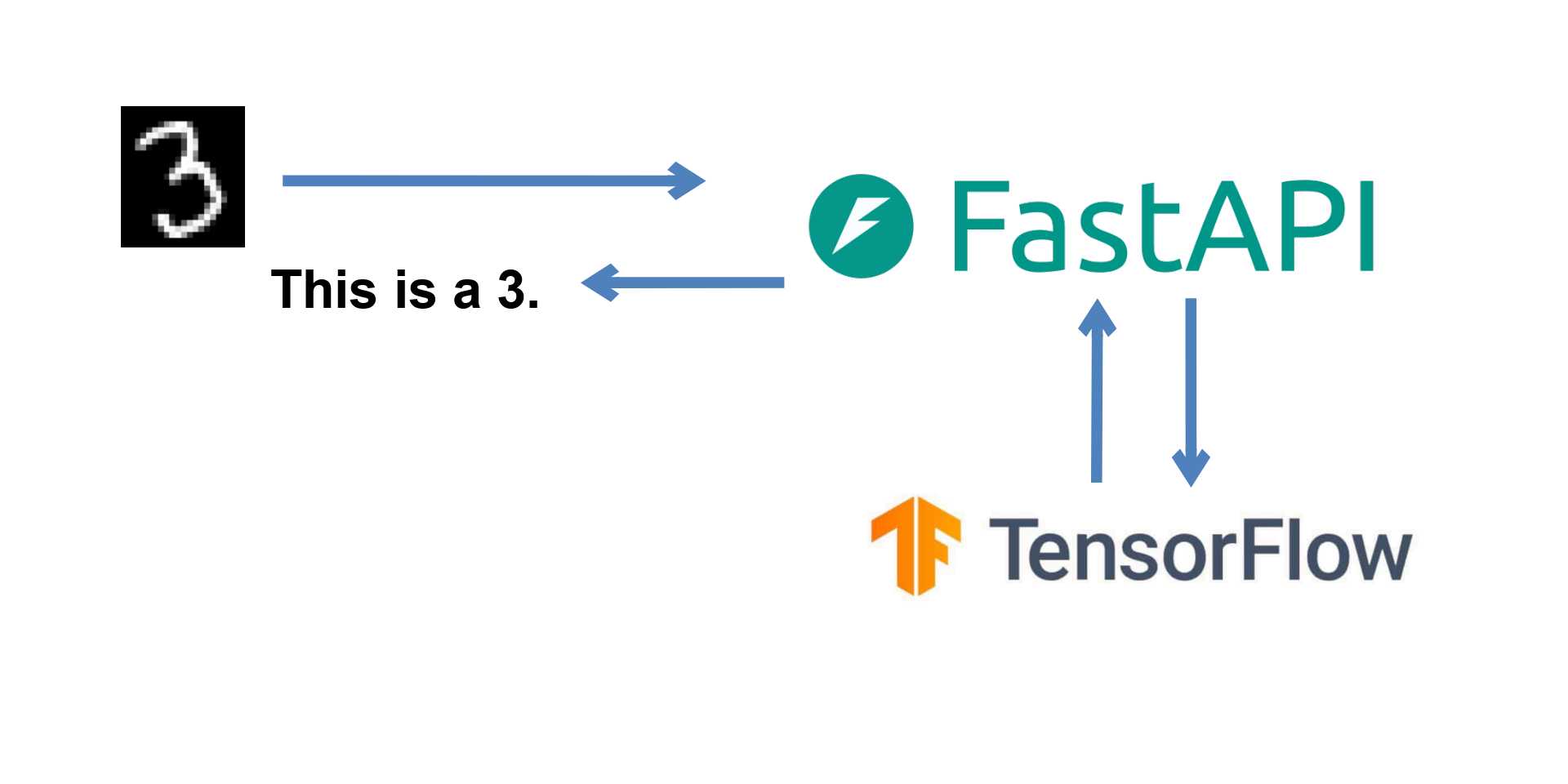
Table of Contents
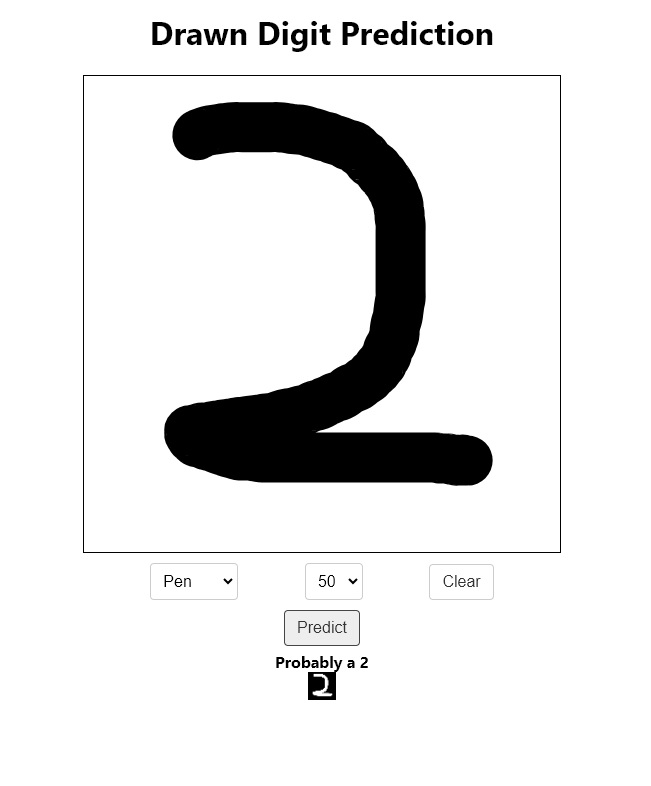
In one of our previous Posts, we built a Convolutional Neural Network in TensorFlow that could classify handwritten digits. Today, we'll wrap it up in a FastAPI Application so that other applications can run inference on our model without having it locally.
The server as well as the inference code are available in this GitHub repository.
Server
We'll divide the codebase into two main directories, the first to contain our model, inference code, and the FastAPI app, and the second to contain tests. Here's the directory structure:
│ requirements.txt
│
├───models
├───src
│ app.py
│ config.py
│ model.py
│ __init__.py
│
└───tests
config.py
requirements.txt
test_apis.pyInstall the Requirements
I would recommend using a virtual environment for this project, you can install the requirements using:
pip install fastapi numpy tensorflow opencv-python pydantic python-multipart uvicorntensorflow is a heavy package, but it's needed as today we'll be using it for inference. It is not necessary to have tensorflow (or torch) while running inference, another option is to use ONNX Runtime as we discuss in this Post. Anyway, for now, let's continue with TensorFlow.
Config
Let's start by working on the src/config.py file. Currently, we'll just have the path to our models directory in this file.
from os.path import dirname, join as path_join
models_dir = path_join(dirname(dirname(__file__)), "models")Model
Next, we define our TensorFlow (Keras) model in the src/model.py.
from keras import optimizers
from keras.layers import Conv2D, MaxPooling2D, Dropout, Flatten, Dense
from keras.models import Sequential
class CNN(Sequential):
def __init__(self):
super().__init__()
self.add(Conv2D(10, kernel_size=5, input_shape=(28, 28, 1)))
self.add(MaxPooling2D(pool_size=(2, 2)))
self.add(Conv2D(20, kernel_size=5))
self.add(MaxPooling2D(pool_size=(2, 2)))
self.add(Dropout(0.5))
self.add(Flatten())
self.add(Dense(50, activation='relu'))
self.add(Dropout(0.5))
self.add(Dense(10, activation='softmax'))
self.optimizer = optimizers.Adam(learning_rate=0.001)
self.compile(optimizer=self.optimizer, loss='sparse_categorical_crossentropy', metrics=['accuracy'])One thing to note is that you can directly import an exported Keras model, instead of defining the model yourself and then loading its weights. But, I prefer to have to model defined in the codebase, this way we know what we are working with.
FastAPI App
The final part of our server is the FastAPI application and the inference code which we will define in src/app.py. Let's import the required packages, initialize the model, and load its weights.
from os.path import join as path_join
import cv2
from fastapi import FastAPI, File, UploadFile
from fastapi.responses import JSONResponse
import numpy as np
from .config import models_dir
from .model import CNN
app = FastAPI()
MODEL_WEIGHTS_FILE_PATH = path_join(models_dir, "training_id", "epoch-epoch_number.h5")
model = CNN()
model.load_weights(MODEL_WEIGHTS_FILE_PATH)Then, we define a couple of helper functions: one that normalizes Uint8 values to Floats between 0 and 1 and another that can preprocess an image before passing it to the model.
def normalize(x, axis=-1, order=2):
"Taken from: https://github.com/keras-team/keras/blob/v3.2.1/keras/utils/numerical_utils.py#L7-L34"
norm = np.atleast_1d(np.linalg.norm(x, order, axis))
norm[norm == 0] = 1
axis = axis or -1
return x / np.expand_dims(norm, axis)
def preprocess_image(image):
image = cv2.resize(image, (28, 28))
image = image.astype(np.float32)
image = np.array([image])
image = normalize(image, axis=1)
return imageThe normalize function that we have defined is the exact same as keras.utils.normalize. This is, once again, a personal preference, as I would like to not have an additional dependency in the inference code.
Finally, we can create the route that will perform the inference.
@app.post("/api/run-inference")
async def run_inference(file: UploadFile = File(...)):
file_contents = await file.read()
np_arr = np.frombuffer(file_contents, np.uint8)
image = cv2.imdecode(np_arr, cv2.IMREAD_GRAYSCALE)
preprocessed_image = preprocess_image(image)
prediction = model.predict(preprocessed_image)
predicted_label = int(np.argmax(prediction))
return JSONResponse(
content={
"predicted_label": predicted_label,
},
status_code=200
)To start the server, simply run the following command:
uvicorn src.app:app --port=8000 --host=0.0.0.0You should get an output saying that uvicorn is listening at 0.0.0.0:8000.
Testing
FastAPI offers a TestClient that can be used to test the application we just created. However, we want to write more generalized tests that make use of a client-side library like requests to test the APIs.
In the project's root directory, create a folder called tests at the same level as the src directory. We'll work on some configuration setup first. Create a file called config.py in this folder.
from os.path import dirname, join as path_join
data_dir = path_join(dirname(dirname(__file__)), "data")At the same level as the tests directory, create a new folder called data. In this folder, we will create another folder called test_images in which we can place some images of handwritten digits. You can draw these yourself using a tool like MS Paint, just make sure to have a black background with a white foreground.
Next to the test_images folder, create a file called test_images_labels.json. We'll put the ground truth labels of the images in this file. Here's an example labels file:
{
"1.png": 1,
"2.png": 7,
"3.png": 2,
"4.png": 9,
"5.png": 8,
"6.png": 5,
"7.png": 1,
"8.png": 7,
"9.png": 1,
"10.png": 7,
"11.png": 7,
"12.png": 0,
"13.png": 5,
"14.png": 3,
"15.png": 2,
"16.png": 1,
"17.png": 0,
"18.png": 8,
"19.png": 7,
"20.png": 4
}Now, we can work on our TestCase. In the tests directory, create a file called test_apis.py. We'll be using unittest along with requests to test our server.
from json import load as json_load
from os import listdir
from os.path import join as path_join
import unittest
import requests
from config import data_dir
class TestAPIInference(unittest.TestCase):
def setUp(self):
self.url = "http://localhost:8000/api/run-inference"
self.images_dir = path_join(data_dir, "test_images")
self.labels_json_file_path = path_join(data_dir, "test_images_labels.json")
with open(self.labels_json_file_path, 'r') as labels_json_file:
self.labels = json_load(labels_json_file)
def test_inference(self):
num_correct_predictions = 0
num_bad_responses = 0
all_image_names = listdir(self.images_dir)
for image_name in all_image_names:
image_file_path = path_join(self.images_dir, image_name)
with open(image_file_path, "rb") as file:
response = requests.post(self.url, files={"file": file})
if response.status_code != 200:
num_bad_responses += 1
self.assertEqual(response.status_code, 200)
response_data = response.json()
if response_data['predicted_label'] == self.labels[image_name]:
num_correct_predictions += 1
print(
f"Image: {image_name}, "
f"Predicted Label: {response_data['predicted_label']}, "
f"Correct: {response_data['predicted_label'] == self.labels[image_name]}"
)
num_inferred = len(all_image_names) - num_bad_responses
accuracy = num_correct_predictions / num_inferred
print(f"Failed to infer: {num_bad_responses} / {len(all_image_names)}")
print(f"Correct Predictions: {num_correct_predictions} / {num_inferred}, Accuracy: {accuracy}")
if __name__ == '__main__':
unittest.main()The file loads all the labels and then loads the test images one by one, getting predictions from the API and comparing them with the ground truth labels. It is important to note that the test does not fail in case of an incorrect prediction. The purpose of the test is to test if the API is functioning correctly, not how accurate the model is.
Now, with the uvicorn server running, from another terminal, we can run the tests.
python test_apis.pyYou should get an output similar to the following:
Image: 1.png, Predicted Label: 2, Correct: False
Image: 10.png, Predicted Label: 7, Correct: True
Image: 11.png, Predicted Label: 7, Correct: True
Image: 12.png, Predicted Label: 0, Correct: True
Image: 13.png, Predicted Label: 5, Correct: True
Image: 14.png, Predicted Label: 3, Correct: True
Image: 15.png, Predicted Label: 2, Correct: True
Image: 16.png, Predicted Label: 1, Correct: True
Image: 17.png, Predicted Label: 0, Correct: True
Image: 18.png, Predicted Label: 8, Correct: True
Image: 19.png, Predicted Label: 7, Correct: True
Image: 2.png, Predicted Label: 7, Correct: True
Image: 20.png, Predicted Label: 4, Correct: True
Image: 3.png, Predicted Label: 2, Correct: True
Image: 4.png, Predicted Label: 9, Correct: True
Image: 5.png, Predicted Label: 8, Correct: True
Image: 6.png, Predicted Label: 5, Correct: True
Image: 7.png, Predicted Label: 1, Correct: True
Image: 8.png, Predicted Label: 7, Correct: True
Image: 9.png, Predicted Label: 1, Correct: True
Failed to infer: 0 / 20
Correct Predictions: 19 / 20, Accuracy: 0.95Conclusion
We've seen how easy it is to build a FastAPI server that runs inference on our TensorFlow model. If you're looking for a lighter way to run inference, or maybe do it in a language other than Python, you can check out my tutorials on running inference using ONNX Runtime for Python (FastAPI) or Node (Express.js).
See you next time :)