DIY Weighted Load Balancing in Python
Set up a single-node Kubernetes Cluster (minikube) as well as other tools (Kubectl, Helm, KEDA, etc.) on your local machine.
April 17, 2024
04m Read
By: Abhilaksh Singh Reen
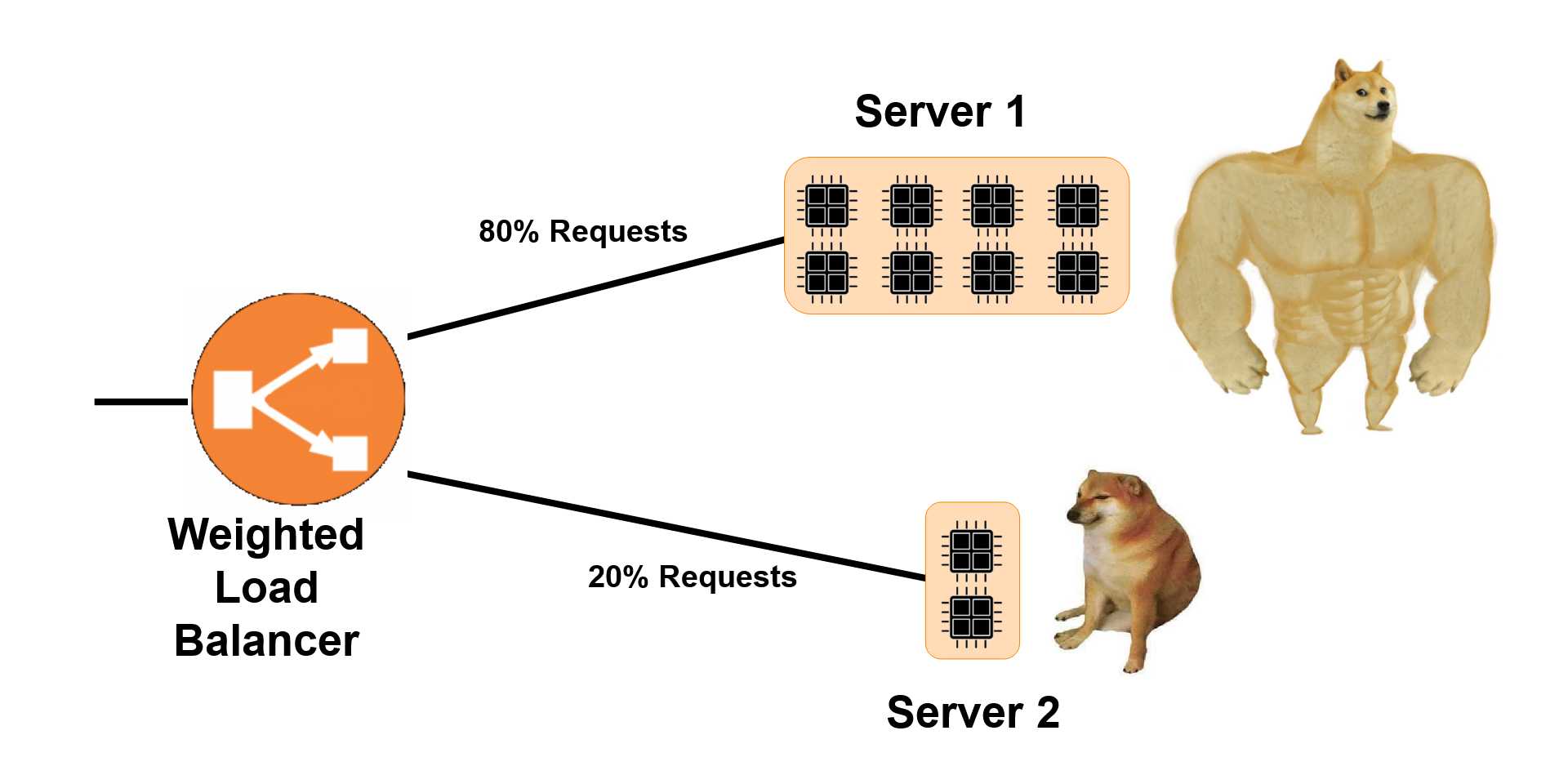
Table of Contents
Load balancing is the process of distributing requests among multiple servers that are serving the same application. Say you have 5 servers with 1 CPU core and 1 GB of RAM in each i.e. all servers have the same computation power. In this case, you could evenly distribute the requests among all servers following a simple Round Robin approach. But, what if some of the machines can take more load than others? For example: consider the following systems:
1) Machine 1: 8 CPUs, 16 GB RAM
1) Machines 2 and 3: 2 CPUs, 4 GB RAM
1) Machines 4 and 5: 1 CPU, 2 GB RAM
We know that Machines 2 and 3 can do twice the computation Machines 4 and 5 can and Machine 1 can do 8 times as much. So it makes sense to router 8 times as many requests to Machine 1 as we are routing to Machine 4 or 5. Today, we'll be writing the logic to do so in Python.
I was asked to do this in an interview once, so I decided to write about it. The code for this Post can be found in this GitHub Repo.
The Logic
Before we write any code, let's quantify things.
If Machines 4 and 5 can do x computation each, Machines 2 and 3 can do 2x each, and Machine 1 can do 8x, we have a total of 14x computation.
weights = [8, 2, 2, 1, 1]So, if we were to get 14 requests, 8 of them should go to Machine 1, 2 to Machine 2, 2 to Machine 3, 1 to Machine 4, and 1 to Machine 5.
So, the probability of the Machines handling requests is as follows:
1) Machine 1: 8/14 = 0.5714
1) Machine 2: 2/14 = 0.1428
1) Machine 3: 2/14 = 0.1428
1) Machine 4: 1/14 = 0.0714
1) Machine 5: 1/14 = 0.0714
All that our Weighted Load Balancer needs to do is route the requests with (approximately) these probabilities.
Server Class
Let's make a dummy server class that has an ID and can track the total number of requests made to it. We'll put this in server.py.
class Server:
def __init__(self, id, weight) -> None:
self.id = id
self.weight = weight
self.total_requests = 0
def make_request(self, request: str):
self.total_requests += 1
return TrueWe can create some objects of this class, make requests to them (according to our logic), and check how many requests were made using the total_requests attribute.
Load Balancing Logic
Most programming languages already have random generators like random.uniform in Python. We can leverage these to distribute the requests as needed.
Our server weights are: weights = [8, 2, 2, 1, 1].
Let's have a running sum of this list: weights_sum = [8, 10, 12, 13, 14].
Now, for each request, we'll generate a random float between 0 and 14. If this lies between 0 and 8, the request goes to Server 0. From 8 to 10, the request goes to server 1, and so on.
In general, if the random value is greater than weights_sum[i - 1] and less than weights_sum[i], the request goes to server i.
target_server = -1
random_value = random_float(0, 14)
if random_value <= weights_sum[0]:
target_server = 0
else:
for i in range(i, len(weights_sum)):
if random_value > weights_sum[i - 1] and random_value <= weights_sum[i]:
target_server = i
breakGreat, but we have to formalize things. Let's create a new file called load_balancer.py.
from random import uniform
from server import Server
class LoadBalancer:
"Weighted Round-Robin Load Balancer"
def __init__(self, servers: list[Server]) -> None:
self.all_servers = servers
self.server_weights_sum = sum([server.weight for server in servers])
self.probability_ranges = self.compute_probability_ranges(servers)
def compute_probability_ranges(self, servers):
probability_ranges = []
last_range_end = 0
for server in servers:
probability_ranges.append({
"serverId": server.id,
"rangeStart": last_range_end,
"rangeEnd": last_range_end + server.weight,
})
last_range_end += server.weight
return probability_ranges
def get_target_server(self):
range_specifier = uniform(0, self.server_weights_sum)
target_server_id = ""
for prob_range in self.probability_ranges:
if range_specifier >= prob_range["rangeStart"] and range_specifier < prob_range["rangeEnd"]:
target_server_id = prob_range["serverId"]
break
if target_server_id == "":
target_server_id = self.probability_ranges[-1]["serverId"]
for server in self.all_servers:
if server.id == target_server_id:
return server
return False
def make_request(self, request):
target_server = self.get_target_server()
target_server.make_request(request)We can initialize our LoadBalancer with a list of servers and make a request using the make_request function. But we don't know it works unless we test it, do we?
Testing
We'll use Python's unittest module to test how good our logic is. In the same folder, create a file called tests.py. We'll make 2 functions, one that can test a single case with a given number of requests and a number of servers, and another (that will be our test case) that calls the other function with a set of inputs.
from random import randint
import unittest
from load_balancer import LoadBalancer
from server import Server
class LoadBalancerTestCase(unittest.TestCase):
def load_balancer_test(self, num_requests: int, num_servers: int):
test_servers = [Server(str(i), randint(1, 15)) for i in range(0, num_servers)]
server_weights_sum = sum([server.weight for server in test_servers])
load_balancer = LoadBalancer(test_servers)
for i in range(num_requests):
load_balancer.make_request(f"request_{i}")
for server in test_servers:
server_weight_ratio = server.weight / server_weights_sum
server_request_ratio = server.total_requests / num_requests
self.assertAlmostEqual(server_request_ratio, server_weight_ratio, 2)
def test_load_balancing(self):
test_inputs = [
[10, 10],
]
for test_input in test_inputs:
self.load_balancer_test(test_input[0], test_input[1])
if __name__ == '__main__':
unittest.main()What we are testing for here is that server_weight_ratio and server_request_ratio are almost equal. \
server_weight_ratio is the weight of a server divided by the sum of the weights of all servers. \
server_request_ratio is the number of requests processed by this server divided by the total number of requests. \
Let's run the file:
python test.pyF
======================================================================
FAIL: test_load_balancing (__main__.LoadBalancerTestCase)
----------------------------------------------------------------------
Traceback (most recent call last):
File "E:\learning\load-balancing\python\weighted_round_robin\tests.py", line 32, in test_load_balancing
self.load_balancer_test(test_input[0], test_input[1])
File "E:\learning\load-balancing\python\weighted_round_robin\tests.py", line 24, in load_balancer_test
self.assertAlmostEqual(server_request_ratio, server_weight_ratio, 2)
AssertionError: 0.2 != 0.16666666666666666 within 2 places (0.033333333333333354 difference)
----------------------------------------------------------------------
Ran 1 test in 0.001s
FAILED (failures=1)Uh Oh. This is a standard problem with logics that rely on random numbers: you get the intended result (even distribution) only if your sample size is big enough.
Let's try a thousand requests with 10 servers.
test_inputs = [
[1_000, 10],
]Still doesn't work. Let's try a million.
test_inputs = [
[1_000_000, 10],
].
----------------------------------------------------------------------
Ran 1 test in 1.225s
OKIn the line where we check if server_request_ratio is equal to server_weight_ratio, we also pass in a third parameter which is the number of decimal places.
self.assertAlmostEqual(server_request_ratio, server_weight_ratio, 2)As the number of requests increases, you should increase the decimal places as well to check if the distribution is indeed as required.
Conclusion
Excellent. So, now we can be sure that if we get a million requests, they will be routed to the servers based on their computational abilities.
See you next time :)